漢王OCR文字識別軟件
下載地址
下載地址

下載漢王ocr文字識別軟件,解壓壓縮包,雙擊.exe文件,根據向導操作,
閱讀許可協議,點擊【是】,進行下一步,
選擇軟件安裝位置,進行下一步,

開始安裝軟件,耐心等待即可。
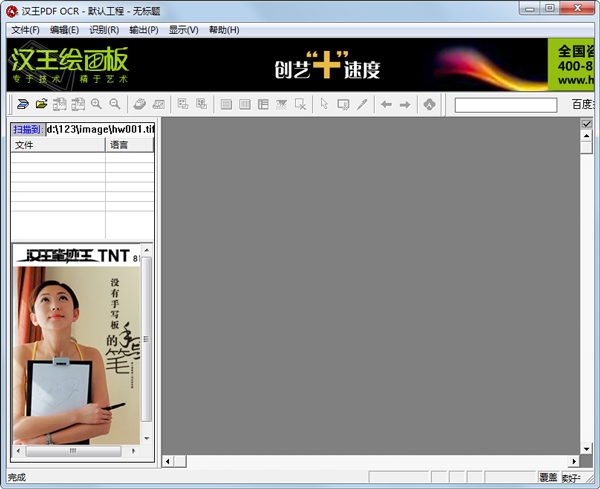
1、打開軟件,
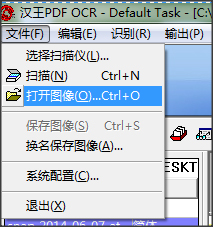
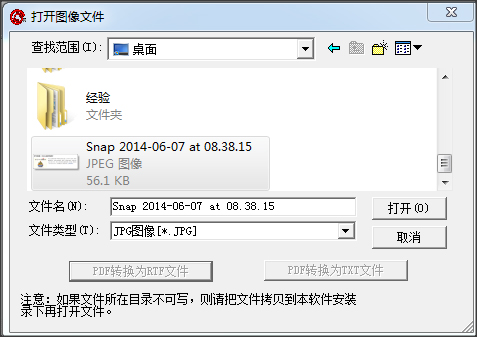
2、點擊文件—打開圖像,將需要識別的文件添加到軟件中,
3、點擊界面上方的識別選項,然后在下拉的菜單欄中點擊開始識別,
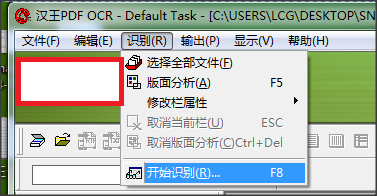
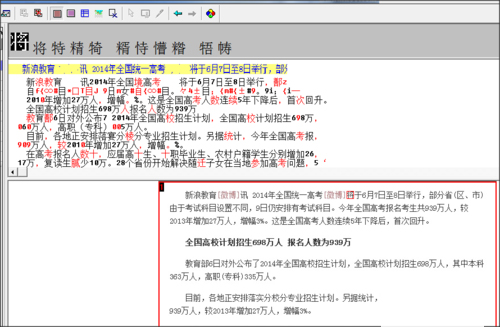
4、軟件將自動識別添加進來的圖片文件上面的文字,識別完成,我們可以對識別錯誤的文字進行修改,
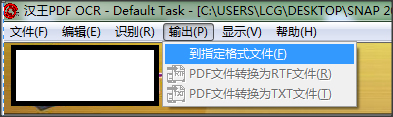
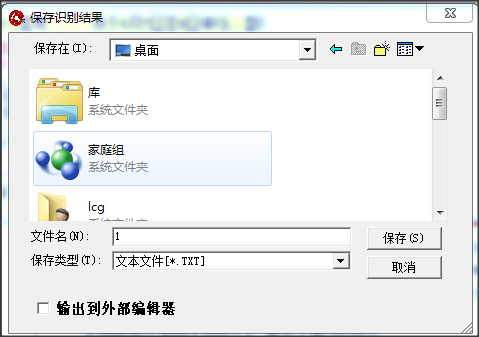
5、修改完成,點擊輸出選項,然后在下拉的選項中選擇到指定的格式文件,選擇合適的保存位置,點擊保存即可。
1.圖像輸入,預處理:
圖象輸入:針對不同的圖像格式,采用不同的存儲格式,壓縮方式不同。前處理:主要有二值化、去噪、偏斜等。
2.二值化:
照相機拍攝的圖片,大多是彩色圖像,彩色圖像包含的信息量很大,對于圖片內容,我們可以簡單地分成前景和背景,為了讓計算機更快,更好地識別文字,我們需要先對彩色圖進行處理,使圖片只包含有背景信息的信息,可以簡單地定義前景信息為黑色,背景信息為白色,這就是二值化圖。
3、去噪:
針對不同的文獻,我們對干燥的定義可有所不同,根據干燥音的特點來進行去燥,稱為去燥。
4.較正傾斜:
因為普通用戶,在拍攝文檔時,都比較隨意,所以拍攝出來的圖片不可避免地會傾斜,這就需要文字識別軟件進行更正。
5、布局分析:
對于把文件圖片分段落下來的過程稱為版面分析,由于文件的多樣性、復雜性,目前尚無一種固定的、最佳的切分模型。
6、切字:
因照相條件的限制,常常會造成字跡粘連、斷筆等現象,極大地限制了識別系統的性能,要求文字識別軟件具有字符切割功能。
7、識別字符:
此項研究,已經是一件很早的事,較早的是模板匹配,后來主要是特征提取,由于文字的位移、筆畫的粗細、斷筆、粘連、旋轉等因素,極大地影響特征提取的難度。
8.重新布局:
大家想要識別的文字,仍然像原來的文檔圖片那樣排列,段落不變,位置不變,順序不變,輸出到word文檔,pdf文檔等等,這個過程被稱為布局恢復。
9、后處理、整理:
識別結果按照一種特殊的語體關系,稱為后處理。
漢王PDFOCR識別準確率高,識別速度快,具有批量處理功能;
提供了對灰度、彩色、黑白三色BMP、TIF、JPG、PDF等多種格式圖像文件的處理;
可以識別三種語言:簡體、繁體、英文;
漢王PDFOCR具有簡單易用的表格識別功能;
它具有TXT、RTF、HTM、XLS等多種輸出格式,以及見即所得的排版功能。
漢王OCR文字識別軟件 v8.1.2.3 綠色破解版45.47MB返回頂部
Copyright © 2009-2025 KKX.Net. All Rights Reserved .
KK下載站是專業的免費軟件下載站點,提供綠色軟件、免費軟件,手機軟件,系統軟件,單機游戲等熱門資源安全下載!
本站資源均收集整理于互聯網,其著作權歸原作者所有,如果有侵犯您權利的資源,請來信告知

 清華紫光OCR文字識別軟件 v9.3 官方免費版
清華紫光OCR文字識別軟件 v9.3 官方免費版 PP論文檢測查重助手 v1.39綠色版
PP論文檢測查重助手 v1.39綠色版 橙瓜碼字純凈版 v3.0.9
橙瓜碼字純凈版 v3.0.9 吉吉寫作(寫小說的軟件) v2.2綠色版
吉吉寫作(寫小說的軟件) v2.2綠色版 一鍵排版精靈(自動排版軟件) v1.0綠色免費版
一鍵排版精靈(自動排版軟件) v1.0綠色免費版 捷速OCR文字識別軟件 v7.5.8破解版
捷速OCR文字識別軟件 v7.5.8破解版 Notepad2 v4.22.01 r4056中文綠色版
Notepad2 v4.22.01 r4056中文綠色版 幻燈片文字提取工具 2.0綠色版
幻燈片文字提取工具 2.0綠色版